Grant Herbert Featured in WAURISA Newsletter
Author: Grant Herbert, GISP Published: January 10, 2019A version of this article was originally shared in the Washington State Chapter of the Urban and Regional information Systems Association (WAURISA) newsletter in fall 2018.
Building the Data Pillager by Grant Herbert
GIS are an insatiable consumer of data, requiring constant updating, management, and organizing. The availability of data as a REST endpoint allows users to consume data from an authoritative source without having to store those data locally. That’s a huge boon to mapmakers everywhere. But sometimes you need a local copy for archiving, making local edits, or adding your own data for analysis purposes. Looking for a suitable dataset to download can be an exercise in frustration, and although I have found that many GIS practitioners are happy to share their data, there are times when it can be hard to even get through to the right person to ask!
Back in 2014, I started building a tool to download data from a REST service. The purpose was to sync a REST service to a local dataset that had to be available offline and that I could modify if necessary. The data were publicly available, but only as an Esri REST service and not as a shapefile or geodatabase format for download. The first iteration was a simple script created specifically for that dataset, but it proved so useful that I started using it for other datasets.
The script—now nicknamed the Data Pillager—was tweaked and modified and converted from a command line script to a toolbox tool, as well as getting some appropriate pillaging help text and messages added to it. I then shared it with some fellow GIS people in an online group, and others, outside my organization, started using it, too. The Esri toolbox containing the tool is available for download from GitHub (along with all the source code). It uses only libraries available in the standard Esri install at 10.3, so it should work on most machines.
The Data Pillager downloads vector data from an Esri ArcGIS REST endpoint and writes the output to a folder (creating a shapefile) or a filegeodatabase. If you have a username and password you can also access secured services (unlike a real pirate, it doesn’t access services without authorization!). It works around the feature number limitations of accessing a REST service (typically returning only 1,000 features at a time for the default setting) by repeatedly requesting the data in chunks allowed by the service, working its way through the list of features by unique ID. Once finished it will combine the data into a single dataset and clean up the individual downloads.
Putting too much pressure on a hosting server may result in a refusal to respond; to mitigate this, you can set the maximum number of times that the program will re-attempt the download until it gives up, as well as the wait period in seconds between tries. Finally, you can enter a SQL data query that can limit the dataset request. The SQL query is not validated, so it is up to the user to get it right! Development is currently slow, but recent enhancements include the ability to download all the sub-services from an endpoint or a folder, handling very long service names, and dealing with duplicate names in the same set of services.
The Data Pillager outputs not only a dataset (or datasets) but also a layer file for each with the symbology of the service. It also generates text files containing the endpoint JSON representation and the symbology, in case you need further information or metadata. As it runs, it will report on progress with vaguely piratical-themed messages.
Running the Data Pillager is straightforward. Download it from https://github.com/gdherbert/DataPillager and make sure that the source is pointing to the correct python script (for easier modification, it is not imported into the tool). If you need a version for 10.1, check the releases and download the first version. When you open the tool, you will see a number of input fields. Only two are required: the URL and the output workspace.
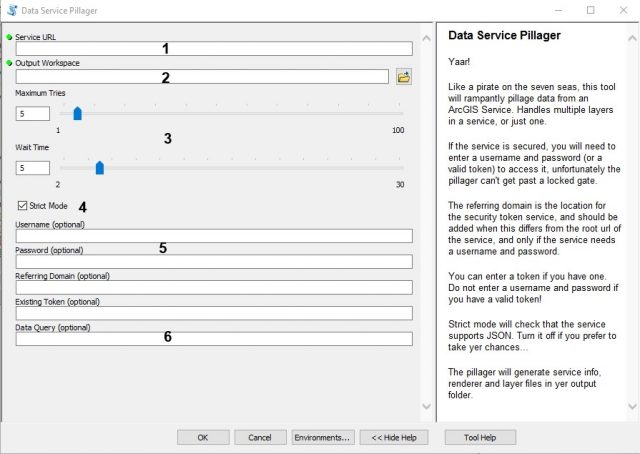
- Required: Enter the rest endpoint URL that has the data. If the URL has sub-services, these will also be downloaded.
- Required: Enter the output workspace path. It is highly recommended that you use a filegeodatabase over a folder. Not only does this give better performance, it also supports longer field names than the shapefile format and is less likely to mangle data. You need to have write access to the folder so the tool can write temp files and the layer output.
- This section determines the number of times the tool will retry a download in event of error, as well as the wait between tries. Modify this only if the server reports too many timeouts.
- When Strict mode is on, the tool will check on whether the service supports JSON format and will proceed only if it does. If the mode is off, it will try anyway (but may fail).
- For secured services, you can enter a username and password, and optionally a referring domain (useful if the referring domain is not the same as the service URL). You can also try entering a token if you have already generated one (useful for Portal services).
- Enter a valid SQL query. This will be passed to the service but not validated. An example of a valid query might be ST_ABBREV IN (‘WA’, ‘OR’).
Contact Us
Contact Us

Grant Herbert, GISP
Director of Technology
(206) 556-2024